

BN层
BN —- Batch Normalization
详情见论文《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》
文章暂未更完。。。。。。
为什么深度网络会需要batchnorm?
我们都知道,深度学习的话尤其是在CV上都需要对数据做归一化,因为深度神经网络主要就是为了学习训练数据的分布,并在测试集上达到很好的泛化效果,但是,如果我们每一个batch输入的数据都具有不同的分布,显然会给网络的训练带来困难。另一方面,数据经过一层层网络计算后,其数据分布也在发生着变化,此现象称为Internal Covariate Shift.(下面解释)
Batch Normalizatoin 之前的解决方案就是使用较小的学习率,和小心的初始化参数,对数据做白化处理,但是显然治标不治本。
BN层的优势
-
可以使用更高的学习率。如果每层的scale不一致,实际上每层需要的学习率是不一样的,同一层不同维度的scale往往也需要不同大小的学习率,通常需要使用最小的那个学习率才能保证损失函数有效下降,Batch Normalization将每层、每维的scale保持一致,那么我们就可以直接使用较高的学习率进行优化。
以前还需要慢慢调整学习率,甚至在网络训练到一半的时候,还需要想着学习率进一步调小的比例选择多少比较合适,现在我们可以采用初始很大的学习率,然后学习率的衰减速度也很大,因为这个算法收敛很快。当然这个算法即使你选择了较小的学习率,也比以前的收敛速度快,因为它具有
快速训练收敛的特性; -
你再也不用去理会过拟合中drop out、L2正则项参数的选择问题,采用BN算法后,你可以移除这两项了参数,或者可以选择更小的L2正则约束参数了,因为BN具有
提高网络泛化能力的特性;(1)dropout是常用的防止overfitting的方法,而导致overfit的位置往往在数据边界处,如果初始化权重就已经落在数据内部,overfit现象就可以得到一定的缓解。论文中最后的模型分别使用10%、5%和0%的dropout训练模型,与之前的40%-50%相比,可以大大提高训练速度。
(2)与上述相同,边界处的局部最优往往有几维的权重(斜率)较大,使用L2衰减可以缓解这一问题,现在用了Batch Normalization,就可以把这个值降低了,论文中降低为原来的5倍。
-
再也不需要使用使用局部响应归一化层了(局部响应归一化是Alexnet网络用到的方法),因为BN本身就是一个归一化网络层;
-
最重要的就是减少梯度弥散和梯度消失。
Internal Covariate Shift
主要描述的是:训练深度网络的时候经常发生训练困难的问题,因为,每一次参数迭代更新后,上一层网络的输出数据经过这一层网络计算后,数据的分布会发生变化,为下一层网络的学习带来困难(神经网络本来就是要学习数据的分布,要是分布一直在变,学习就很难了)的一种现象。
Internal Covariate Shift 和 Covariate Shift 具有相似性,但并不是一个东西,前者发生在神经网络的内部,所以是Internal,后者发生在输入数据上。
Covariate Shift主要描述的是由于训练数据和测试数据存在分布的差异性,给网络的泛化性和训练速度带来了影响,我们经常使用的方法是做归一化或者白化。想要直观感受的话,看下图:
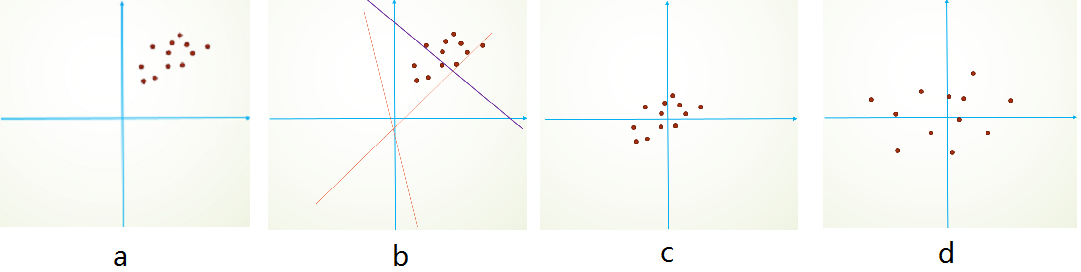 假设我们的数据分布如a所示,参数初始化一般是0均值,和较小的方差,此时拟合的y=wx+b y=wx+by=wx+b如b图中的橘色线,经过多次迭代后,达到紫色线,此时具有很好的分类效果,但是如果我们将其归一化到0点附近,如图c,显然会加快训练速度,如此我们更进一步的通过变换拉大数据之间的相对差异性(图d),那么就更容易区分了。
假设我们的数据分布如a所示,参数初始化一般是0均值,和较小的方差,此时拟合的y=wx+b y=wx+by=wx+b如b图中的橘色线,经过多次迭代后,达到紫色线,此时具有很好的分类效果,但是如果我们将其归一化到0点附近,如图c,显然会加快训练速度,如此我们更进一步的通过变换拉大数据之间的相对差异性(图d),那么就更容易区分了。
所以Covariate Shift就是描述的输入数据分布不一致的现象,对数据做归一化当然可以加快训练速度,能对数据做去相关性,突出它们之间的分布相对差异就更好了。
BN原理
为了减小Internal InternalInternal Covariate CovariateCovariate Shift ShiftShift,对神经网络的每一层做归一化不就可以了,假设将每一层输出后的数据都归一化到0均值,1方差,满足正太分布,但是,此时有一个问题,每一层的数据分布都是标准正太分布,导致其完全学习不到输入数据的特征,因为,费劲心思学习到的特征分布被归一化了,因此,直接对每一层做归一化显然是不合理的。
更不动了….后续歇歇再更。。。☠




