

数据挖掘
简介
大数据呈现的特点通常有4个”V”:体量(volume)、速度(velocity)、多样性(variety)、真实性(veracity)。
体量是指数据量;
速度是指流速,即生成和改变数据的速度;
多样性是指数据生成时的不同类型(货币、日期、数字、文本、图片等等);
真实性是指有机分布式流程(比如数百万人注册服务或免费下载)生成数据的事实。
用于预测和分析的方法有很多,每种方法都有自身的优缺点,方法的有用性取决于以下因素:数据集大小、存在于数据中的模式类型、数据是否满足方法的某些基本假设。数据噪声大小以及数据分析的特定目标等等。
根据数据性质组织的数据挖掘方法如下图:
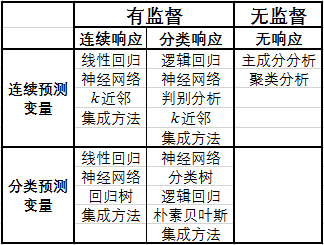
数据挖掘的步骤
- 要了解项目的目的。研究的问题是什么?利益相关者会如何使用分析的结果?谁会收到结果的影响?分析是一次性还是可持续的过程?
- 获取分析中使用的数据集。可能涉及随机抽样。
- 探索、清洗和预处理数据。数据是否合理?缺失数据如何处理?是否有异常值(脏数据)?
- 按需考虑是否需降维。剔除无用变量或者转换变量等。
- 确定数据挖掘的任务(分类、预测还是聚类等)
- 数据分割(用于监督学习)。按合适的策略将数据集分为训练集、验证集、测试集、
- 选择合适的算法(回归、神经网络或者聚类等)
- 使用算法执行任务。这通常是一个迭代过程,尝试多种形式,根据结果不断修正改进。
- 解释算法的结果。这包括选择出最佳算法,并且在可能的情况下,在测试集上测试最终的算法。
- 部署模型。将模型整合到可操作系统,并在实际数据上运行来产生决策或行动。
预测效果评估
用于数值预测的模型的性能评价
一个好的预测模型应该预测准确度上胜过基准(平均值)
预测准确度的测度:
● MAE/MAD/AAE(平均绝对误差/偏差):对误差的绝对值求平均,表明了平均误差的大小。
● 平均误差:因为保留误差的符号,正负会有所抵消,因此该指标也是一种对响应预测结果是高估还是低估的指示。
● MAPE(平均绝对误差百分比):误差除以真实标签值的绝对值的平均,表示了预测值用真实值偏离程度的百分比。
● RMSE/RASE(均方根误差):误差平方的均值再开方,该指标是通过验证集而不只是训练集计算出来的。
● SSE(误差平方和)
用于类别预测的分类器的性能评价
可以参见我的博客《机器学习常用评价指标》文章。
用于排序的分类器的性能评价
统计数据基本概念
分为以下四种类型:
1)定类数据:表现为类别,但不区分顺序。例如:性别数、班级数等
2)定序数据:表现为类别,但有顺序。例如产品按一等品、二等品、三等品计数等。
3)定距数据:表现为数值,可进行加、减运算。如:身高、体重、收入等。
4)定比数据:表现为数值,可进行加、减、乘、除运算。
前两类说明的是事物的品质特征,也称为定性数据或品质数据;后两类说明的是现象的数量特征,统称为定量数据或数量数据。




