

R语言学习
工作目录设置
setwd(): 设置当前工作目录,数据和程序都将保存到该目录下
getwd(): 显示当前目录
安装包调用:install.package(“包名”) 等价于 library(包名)
ls(): 显示内存中的对象
ctrl + L: 清屏
rm(): 删除内存中的对象,包括变量、数据框、函数等
options(digits=): #显示小数位数,默认为7,全局。(round(value, 4) #显示4位小数,局部。)
注释
单行注释: 用一个’#’;
大段注释: if(FALSE){ 代码 }
输入数据
★ R 语言对大小写敏感!!!
-
用向量函数c命令直接输入
X = c(164,162,186)
-
读取文件
● 文本数据(.txt)或者某个网页上的文件:
read.table(filename, header=T), header=T用来指定第一行是标题行。
read.table(文件网址)
● 表格(.xlsx, .csv):
read.csv(filename)
-
读取其他统计软件数据
首先要调用foreign包:library(foreign)
例如:read.spss(“SPSS数据文件名”)
数据形式
数据类型
数值型(默认为双精度)、字符型(单引号或双引号均可)、逻辑型(T/F)、日期型、缺省值(NA,任何NA的运算结果都是NA)。
数据对象
向量(vector)
● 利用c()函数;赋值符号:<- 或者 -> 或者 =。也可用assign()函数对向量赋值:assign(“w”, c(1,2)) # w=[1,2]
● 常见的正则序列,可以用”:”符号。
i = 1:9 # 1,2,3,4,5,6,7,8,9
i = 9:1 # 9,8,7,6,5,4,3,2,1
● 利用seq()函数产生有规律的序列: seq(起始值, 终止值, by=)(by表示步长),当步长=负数时,降序; 若要固定数列长度: seq(起始值, 终止值, length=长度)或者seq(起始值, by=,length=)
● rep(x, times):x表示要重复的对象,times是重复的次数。
● length():返回向量长度; mode():返回向量的数据类型
-
因子(factor)分类型数据经常要把数据分成不同的水平或因子。比如性别分为男、女两个因子。
生成因子:factor(data,[levels, labels, …]), levels是因子水平向量,labels是因子的标签向量,可选。
可以用函数levels()列出因子水平。
-
矩阵(matrix)
● matrix(data=NA, nrow=1, ncol=1, byrow=FALSE, dimnames=NULL)
data是必须,其他可选,nrow表示行数,ncol表示列数,byrow默认表示按列排列,dimnames用于更改行列名。
例:matrix(c(1,2,3,4,5,6),nrow=2,ncol=3,dimnames=list(c("R1","R2"),c("C1","C2","C3")))
C1 C2 C3
R1 1 3 5
R2 2 4 6
如果令byrow=TRUE,则按行排列,第一行R1:1 2 3,R2: 4 5 6
● diag(A):当A是向量是则生成对角矩阵;但当A是矩阵时,返回对角元素;当A为数字时生成单位阵。
● A×B表示矩阵对应元素相乘;A%×%B表示矩阵相乘;solve返回矩阵的逆矩阵,若矩阵奇异则无法求得结果。
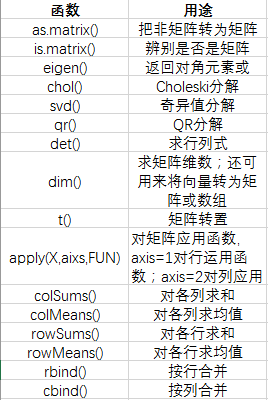
● 常见函数:
-
数组(array)带有多个下标的类型相同的元素的集合,一维数组即向量,二维即矩阵。array(data=NA, dim=, dimnames=NULL), dim表示维数,dimnames更改维度名称。
-
数据框(data frame)★ 重要(下面重点介绍) -
列表(list)列表是一个对象的有序集合,列表中包含的对象又称为它的分量,分量可以是不同的模式或类型。
● 创建:list(变量1=分量1,变量2=分量2,….)
● 访问:
若访问某一个分量集合,LST[[分量索引]];若访问某分量中的某部分元素,LST【【分量索引】】【元素索引】;
由于分量可以被命名,所以可以利用LST$分量名访问。(分量名还可以简写,只要能区分即可)
● 简单函数:length()、mode()、names()分别返回列表长度(分量的数目)、数据类型、列表成分名字。
数据框
● 定义:
data.frame(data1, data2,…)
● 显示:
dim(frame) #显示数据框的维数
nrow(frame) <=> dim(frame)[1] #数据框的行数
ncol(frame) <=> dim(frame)[2] #数据框的列数
names(frame) #显示数据框的变量名
head(frame, num) #显示前num行数据,默认显示前6行
tail(frame, num) #显示后num行数据,默认显示后6行
● 创建数据库中的变量:
1)$法: frame$新变量 = value
2) transform法: frame = transform(frame, 新变量=value)
● 取值:
1)下标法:
frame[i,j]取frame的第i行j列数据;
frame[i,]选取第i行; frame[,j]选取第j列
frame[c(),]选取矩阵数组中的行
2)$法(记号法): frame$变量名
3)subset法(子集法): subset(frame, 变量名满足的条件)
4)attach法:用于解析数据框中的所有变量,此后的变量名可以直接使用
attach(frame)
mean(变量名) #取某一列变量的均值
detach()
5) with法:也是解析数据框中的所有变量,{}中变量名可直接使用
with(frame, {语句体})
● 剔除变量:
下标前面加‘-’号即可。该方法并未从数据集中真正删除,本质也是一种数据选取。
frame[-i,]剔除第i行数据; frame[,-j]剔除第j列数据
frame[c(-1, -3),]剔除第1和3行数据
frame[-i, -j]剔除第i行和第j列的数据
● 删除变量:从数据集中删除
给变量赋值为NULL:frame$变量 <- NULL
● 分组:将数据框中某组变量按一定条件分组,以新变量加入
1)within():
frame <- within(frame, {
新变量=NA;新变量[cond1]<-value;....
})
2)cut()函数
frame$新变量 = cut(frame$旧变量, breaks=c(分段值))
数学运算
运算符:+ - × / ^ x%%y(求模取余) x%/%y(整除) !(取非)…(其他跟常用的一样)
还有基本函数以及积分,求导,组合,求根等函数,有需要自查。
字符函数: 大小写转换、选取特定位置的字符、将字符串转为命令执行(先用parse()将字符串转为表达式,再用eval()对表达式求解。)
日期: Date类型的数据可以进行算数运算,利用format函数将日期转为“星期日,22 七月 2007”的格式:format(Sys.Date(), format=”%A %d %B %Y”)
函数
-
自定义:
函数名 <- function(参数1, 参数2, ...) { 函数体 函数返回值 } -
循环语句:
for(变量 in 取值向量) { 表达式 } -
分支语句:
if(cond) statement
if(cond) statement1 else statement2
ifelse(cond, yes, no): cond为真,输出yes的值,否则输出no的值。
数据整理
-
排序
sort(): 只针对对单个变量(向量)排序
order(): 还可以对多变量(数据框)排序
默认为升序;若要降序,可在变量名前加’-‘,或者用参数decreasing=TRUE.
-
合并
merge(frame1, frame2, (by=‘变量名’)): 按横向合并两个数据框,而且要求两个数据框有一个或多个共同变量,可以用by指定按某列合并;
cbind(frame1, frame2): 横向合并任意两个数据框(矩阵),但要求数据框(矩阵)必须有相同的行数;
rbind(frame1, frame2): 纵向合并任意两个数据框(矩阵),但要求数据框(矩阵)必须有相同的列数,数据框必须有相同的变量。
-
缺失值处理
is.na(frame或者frame$变量)用于识别是否包含缺失值
na.omit(frame)用于移除缺失值,按行删除含缺失值的




